


Iceberg Integration with Spark and DuckDB Today
Looks like things are taking off


I’ve written a decent amount about Iceberg, DuckDB, and Spark over the last year or so. And each time I’ve tried integrating Iceberg into Spark or DuckDB, it required a good amount of elbow grease. Well, I decided to take a peak again to see where things stand (circa late 2024), and I’m noticing now that both Spark and DuckDB have improved a lot on the underlying plumbing to get Iceberg working. What do I mean by “plumbing”? This is the mundane infrastructure setup requirements to just get Iceberg running e.g. jar files, configurations, etc.
For more context, over a year ago, I went down the rabbit hole of building out a full docker container solution just to get the Iceberg pyspark runtime to work, which you can go explore here. As much as I enjoy building a fully “contained”/container solution, the amount of effort it required left a sour taste in my mouth, given if Iceberg is supposed to be the future of open table formats. One would think with python especially, it should just be a walk in the park…
How are we looking today?
Well, fast forward to today and it is much easier and way less plumbing. Here is a snippet of the actual code you need to get a full iceberg pyspark session up and running (no containers, no having to go manually hit maven for jar files directly). All of this is managed by the pyspark session which is great:

That’s cool bro, but let’s put it to use
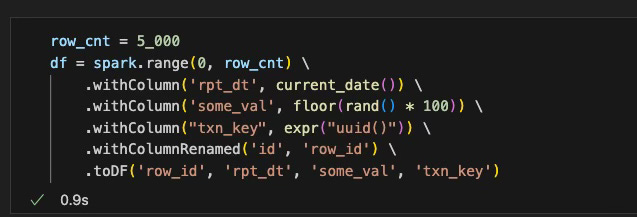
Now that we have our iceberg pyspark session up and running, let’s go build ourselves a table. To do this, we will first generate a simple 5k row dummy dataset as follows:
And before we write the table, we need to generate in Iceberg what is known as a “namespace”. Think of it as a database schema in SQL Server land:

Alright, now let’s go write the dataframe to a table:
Interestingly enough, when you run this command the first time, it does succeed but the spark stack throws a “warning”/soft error that says “Error reading version hint file”. The file does get generated with the df.writeTo command and subsequent runs on this table do not produce said warning.
Ok, I thought you mentioned DuckDB though?
Now that we have our dataset generated via spark, what does the state of affairs for DuckDB look like if we want to read that data and do some analytics?
As a side note, last time I checked the duckdb Iceberg extension, it seemed very buggy. You can read more about that earlier attempt here.
But today is a new day, and I’m cautiously optimistic that we might get somewhere with the Duckdb iceberg extension…so let’s give it a try. First thing we will do is create a duckdb connection and install the iceberg extension as follows:

And now the moment we’ve been waiting for
Will a query on our iceberg table succeed or fail with some obscure error?
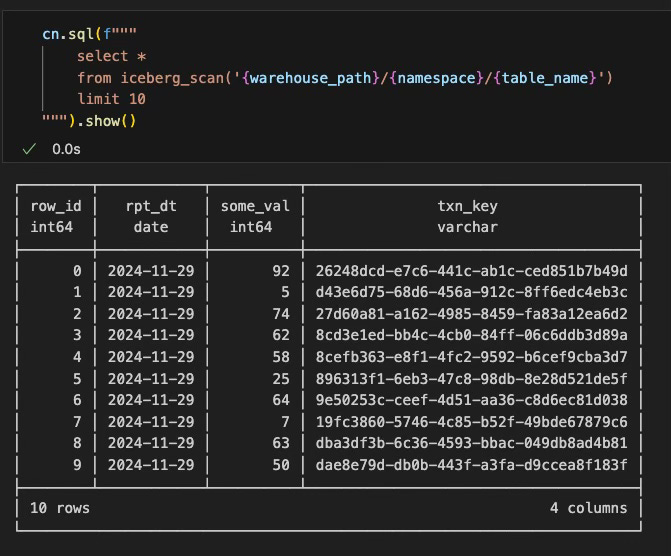
Wow…it worked without any issues. I’m glad this extension is starting to come around. It seems like we will see a world one day where both Spark and DuckDB can play their respective roles with data processing and data analytics for Iceberg tables. And who knows…maybe someday soon the duckdb iceberg extension will be able to WRITE to iceberg tables. When that day comes, I will welcome it, as I see DuckDB as a great substitute on data processing for smaller workloads where you don’t need a sledgehammer to crack a peanut … a.k.a. spark.
Other Thoughts and Wishlist
I’m glad that as of today (circa late 2024), getting Iceberg up and running in spark is easier. The ability by a simple config to tell spark to go fetch the required iceberg runtime lowers the barrier of entry for more engineers that want to give iceberg a try. In terms of future usage of these packages, here is small wish list:
First and foremost, WRITE support on DuckDB to Iceberg
DuckDB not requiring the iceberg extension load at all. Native function such as iceberg_read()
Ability for DuckDB to connect, read, and write to a metadata catalog such as AWS Glue, Polaris, or Google BigLake. This way, I don’t have to know a corresponding S3/GCS location for the table. There is already work under way for it to connect to Unity, which can be found here.
Spark not requiring all those iceberg configs up front. Just a simple df.writeTo(format=’iceberg’, location=’~/some_folder/data’) and that is it.
Here’s a link to code that was discussed in this article.
Thanks for reading,
Matt