


As much as I like developing and testing spark jobs on a nice cloud native UI web browser such as Databricks, AWS Glue, or Google’s cloud, there are drawbacks to the testing and iteration phase on those platforms:
Latency: Sometimes you spin up a notebook in the web browser and the hamster wheel on the screen just spins for several minutes and you have to logout/log back in to fix it
Iteration speed: locally I can start and stop spark within a couple seconds when I need to make configuration changes. In the cloud, this is usually somewhere between 2-5 minutes depending on who’s service you are working with.
Goofy and uninformative errors such as AWS Glue’s notorious “095 dataframe failed to write”…good luck troubleshooting that nonsense
Now don’t get me wrong; these cloud services also make setting up spark jobs a heck of a lot easier than doing it locally, since they usually hide all the massive spark configs behind the scenes to save you the headache of trying to guess yourself what special combination works.
Me attempting to guess the dozen or so spark configs to make my stuff work

They also handle the integration seamlessly with their backend object store system (whether that is S3, GCS, Azure Blob). That is another complex effort on its own.
Given all that talk above, I forged down the road of figuring out how to actually run spark locally from my laptop to write Iceberg tables directly to GCS (no saving off locally, then uploading). It was a lot of trial and error; there are not many examples out there and the few that I found were either years outdated or only supported using a google service account instead of my default application credentials, which is a security no-no.
The Setup
For this article, I have divided the process into 3 natural data engineering phases:
Generate some dummy data in GCS for our pipeline to read
The actual pipeline - reads the dummy data, aggregates it up, and writes it out to iceberg in gcs
Validation - what good is the data anyways if we don’t ensure it’s as accurate as we can make it?
Part 1: Generating Test Data
This part was pretty straight forward. I used duckdb and the tpch extension to generate a couple of raw parquet files in GCS. This is what the code looks like (nothing too fancy here). I really like how tpch is built-in via an extension. It makes working with fake datasets brain-dead easy:
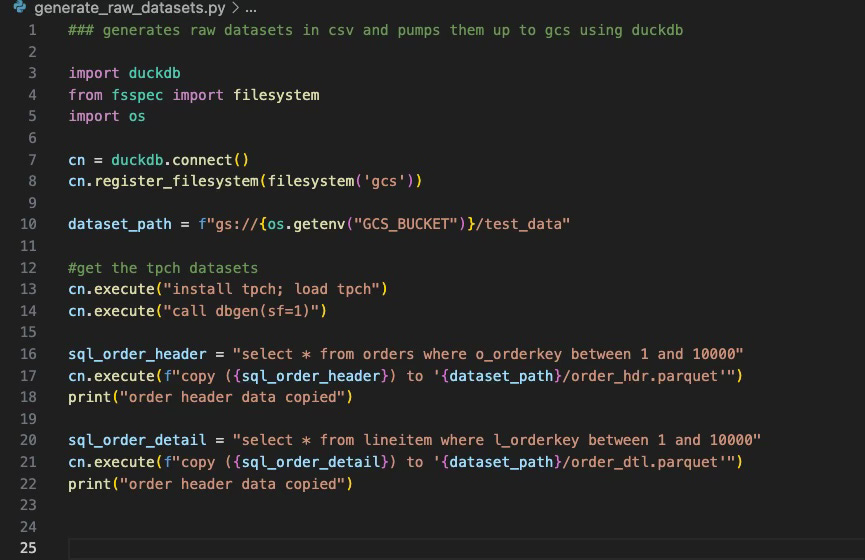
Part 2: The Pipeline
This is where things get tricky and where I felt like I had to whack my head against a desk several times to make sense of all the spark configs. I’ve broken this down into a couple sub-parts to help make sense of it all…
Part 2a: The Packages You Need
To effectively solve the problem with the data pipeline and spark, I took a crawl/walk/run approach, meaning I’ll first work on getting local pyspark to write a simple parquet file to GCS; once I have proved that out, then I’ll introduce Iceberg as the next layer.
When I first started googling the packages I needed for local pyspark to talk to gcs directly, I found an example on google’s official docs here that mentioned to just grab the “gcs-connector-hadoop3-latest” and all my problems would be solved for local development.
So I downloaded that package, and added it to the spark.jars config and tried to authenticate via application default credentials. That ended up being a no-go; I was getting random “can’t initialize google Hadoop filestorage” errors when spark tried to write a simple dataframe. I noticed from the docs that Google had provided though that they were using a service account; so I tested that theory and created a service account to do the work and voila…their package then “worked”. I say worked in quotes because as I mentioned earlier, I don’t like using service accounts for security reasons. If they fall into the wrong hands, that could be a major problem for you.
I then went back to the Google doc I linked above and by random chance clicked the “specific version” link in the screenshot below:

That brought me to a GitHub repo for google cloud’s dataproc product. In there, the first link was “gcs-connector-3.0.4-shaded.jar”…So I figure…why not roll the dice and give this one a try 😆?
Lo and behold, that jar worked on using application default credentials to authenticate and write parquet files directly to gcs with pyspark!
One thing I’ve learned from all the cloud providers and spark is there usually lurks a specific jar somewhere in their docs that is not clearly outlined saying “Hey You! Download me to solve all your problems”. That’s the one you usually need.
Alright, so at this point, we have pyspark working locally to read/write to GCS. Now, let’s introduce Iceberg into the mix and see if we can get this over the finish line. To do this, I’ll leverage the spark.jars.packages config which will use ivy to download the iceberg spark runtime seamlessly. Below is a screenshot of the code creating our glorious spark session, with all its configs to allow us to locally read/write iceberg tables to GCS:
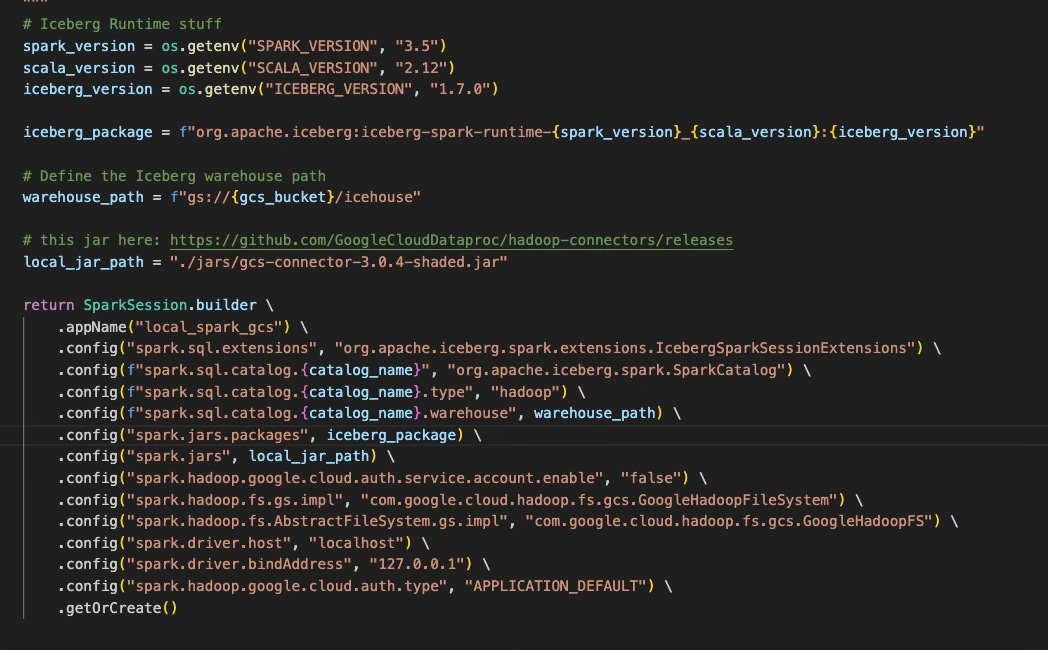
Yes, you are seeing 1 dozen configs there; this is more/less the underlying sausage making that cloud providers obfuscate for you when you use their nice web browser notebook UI.
Part 2b: Alright, Let’s Create an Iceberg Table in GCS
To do this, I wrote a function in python called “process_data”, which simply creates our spark session, then reads the raw datasets we created back in part 1, aggregates them up, and writes the results to our GCS iceberg warehouse. That code is below:
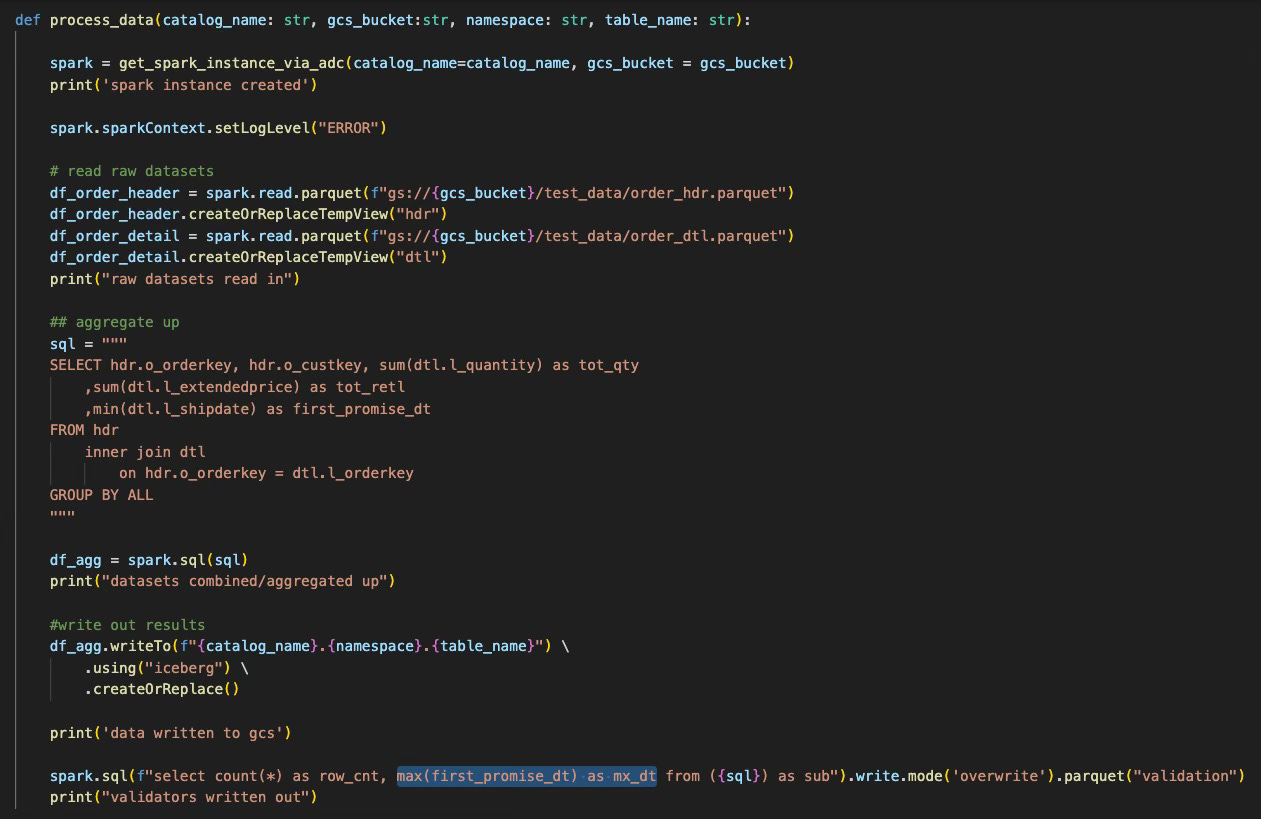
You will notice I also threw in a validation step at the end that writes out a couple values to a parquet file that we will use later downstream in our validation phase. From my laptop, this takes about 10 seconds for the code to run and write the Iceberg table in GCS.
Part 3: Validation
I always like to throw in a validation (unit test/whatever they call it these days) section when building out these prototypes to ensure that even though the first process says it ran without errors, did it actually write the data like it said it did?
To do this, I’m going to leverage duckdb again. I know I’ve ranted in the past that DuckDB’s Iceberg extension is not that great due to it looking for a “version-hint.txt” file that many engines are no longer providing. There are some open issues on GitHub currently, where people are working this problem with some creative solves on guessing the current version. But, for today’s demo, our spark session actually writes the version-hint.txt file so I figured I’d give Duckdb’s extension another go. Below is our simple validation script that samples data as well as perform a couple assertions to ensure the data was accurately written to GCS:
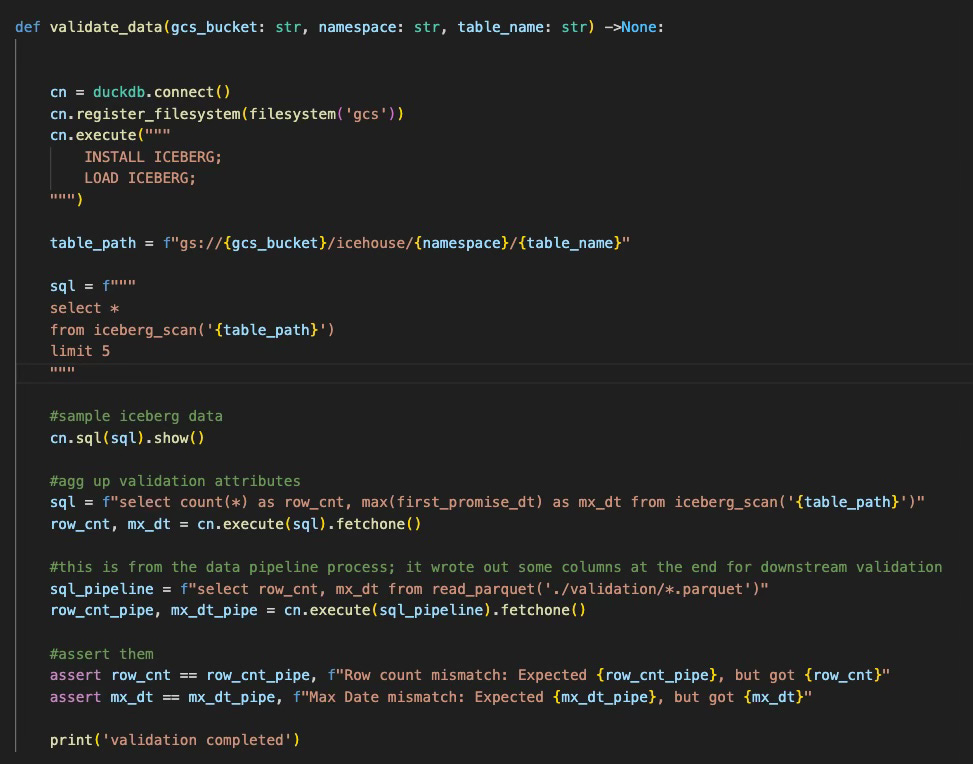
And now, let’s run our validation script and see what happens:
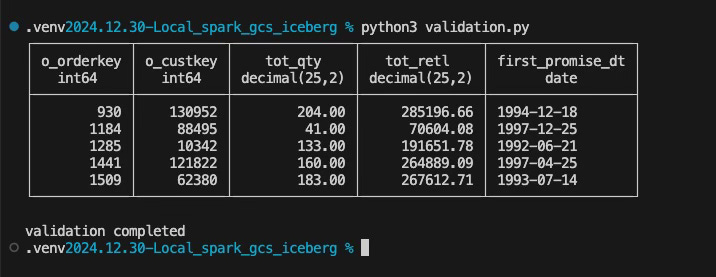
And voila!
Summary
In this article, we were able to demonstrate how to run pyspark locally to write iceberg tables to GCS directly. Additionally, we were also able to use DuckDB to both generate our test datasets as well as perform our validation.
In terms of practical use, I think with this setup, one could easily develop their spark scripts locally if they are targeting Iceberg on GCS, but with the simple caveat of ensuring when you test locally, you don’t try to use datasets too large for your local workstation; when pushing up to production in the cloud and scheduling, the team could have a simple function that swaps how the spark session is created.
Additionally, and I know this is in the hopper, it will be great for duckdb one day to be able to write to iceberg natively; imagine if we could run something as simple as this from duckdb:
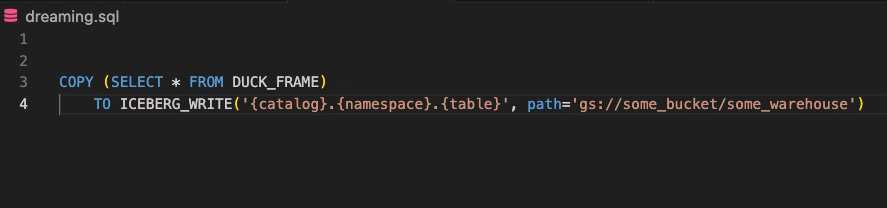
That is truly what I’d call a “game changer”.
Here’s a link to all the code we discussed in the article:
Thanks for reading,
Matt